Louie De Luna
AGNISYS Chief Product Evangelist

Louie De Luna
AGNISYS Chief Product Evangelist
The conventional von Neumann architecture has been the workhorse of computing for several decades
—
But with the advent of AI applications and big data the entire industry has put a spotlight on its limitations. Since massive amounts of data need to travel back and forth between the CPU and memory, the resulting latency and power consumption became major issues. One of the powerful convolutional neural networks (CNN), Alexnet, requires 68M total weights (parameters) and 724M total MACs for a single inference process – a mere average requirement compared to other CNNs such as VGGNet which requires 138M total weights and 15.5G total MACs.
New chip architectures and technologies are now emerging to address these issues known as the “von Neumann bottleneck” or the “memory wall” problem. The Google TPU is based on systolic arrays that provides up to 420 Teraflops, the Graphcore IPU is based on Bulk Synchronous Parallel (BSP) technology that provides up to 125 Teraflops and IBM Zurich Lab is working on a new AI chip based on in-memory computing.
But as the world of computing and AI wait for the new chip architectures to mature, the memory wall problem is still a real pain. Startups without the backing of deep pockets will need to come up with other ingenious ways in order to be competitive.
A popular strategy used for datacentre acceleration is to repurpose existing von Neumann architectures by implementing some of the register files as on-chip SRAM as opposed to standard flip-flop cells. This will free up a considerable area on the die that can be used to implement more functional blocks for acceleration. There are two base categories of register files in today’s SoCs: dynamic and static registers.
Benefits of SRAM-based Register Implementation
Implementing register files as SRAM as opposed to standard flip-flops provide the following significant benefits:
Sample Implementation in IDesignSpec
Implementing registers using SRAM is not an easy task as the creation of the structure and interface requires a lot of automation. The registers implemented as SRAM need to also connect with the registers implemented as flip-flops. An example of how this can be done in IDesignSpec is described below with several components shown in Figure 1.
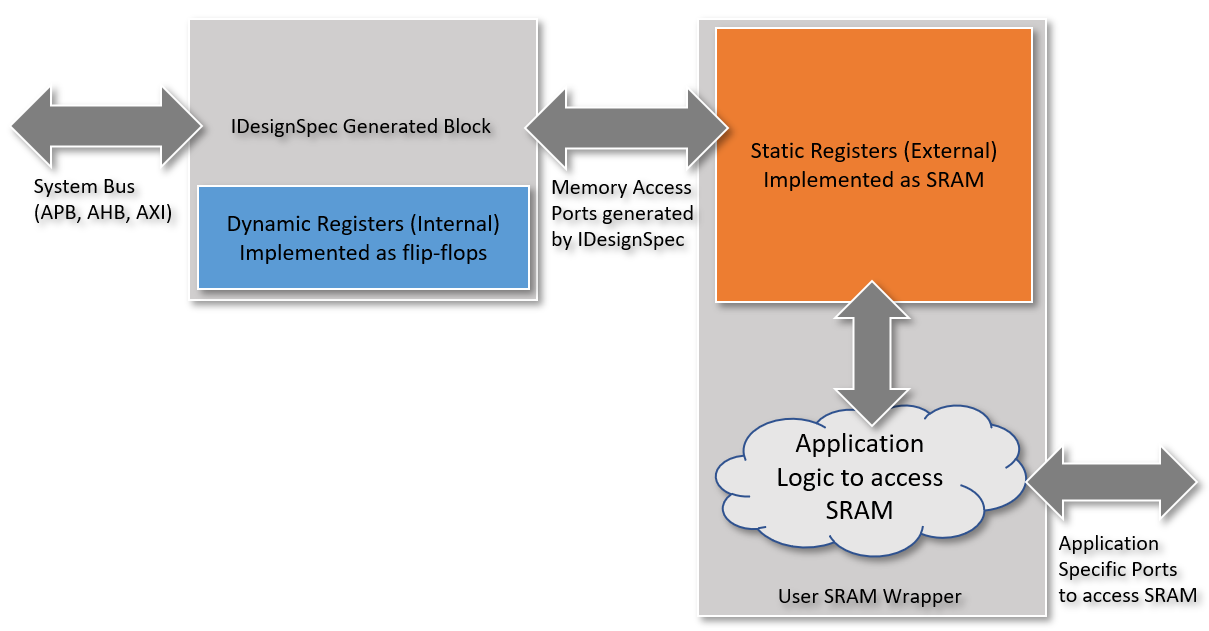
Figure 1: Implementation in IDesignSpec using SRAM Wrapper
A more specific example of a register file structure is shown in Figure 2 which consists of:
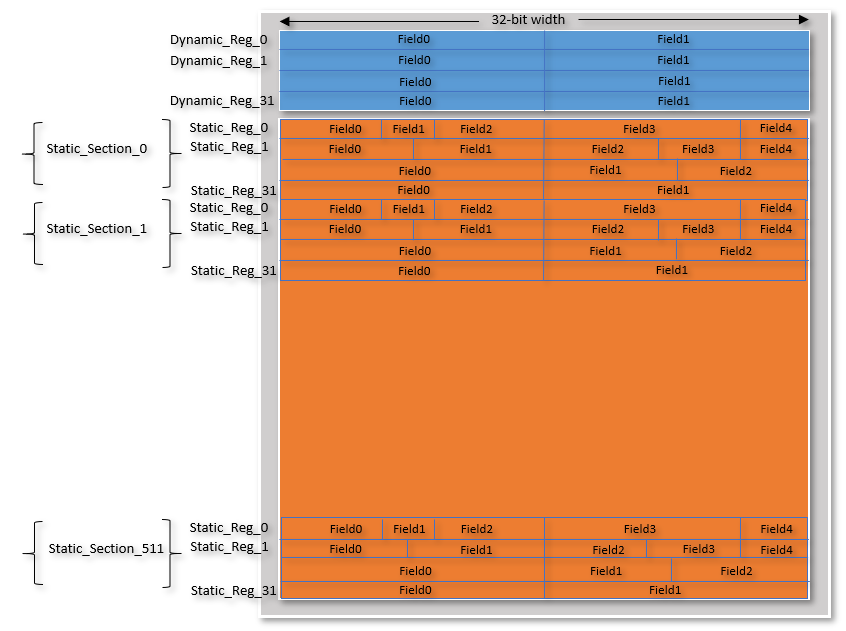
Figure 2: Register File Example Structure
Figure 3 shows how the Dynamic and Static Registers can be defined in IDesignSpec using Excel Editor. Using properties {EXTERNAL=true; repeat=512} in the description column repeats the Static section 512 times and makes “Static_Section_0, Static_Section_1, … Static_Section_511” as address placeholders only where no physical registers are implemented inside the IDesignSpec generated block. Only ports are generated by IDesignSpec.
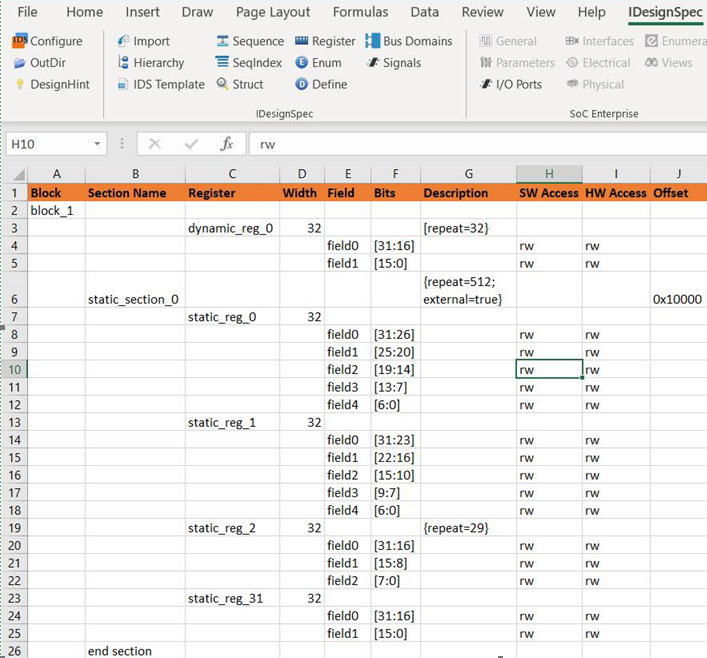
Figure 3: Register File Example Definition in IDesignSpec Excel
Once the specification is completed using IDesignSpec Excel Editor then the user simply needs to select the desired system bus (AMBA-APB, AHB, AXI, TileLink or Proprietary) and generate the required output code including RTL, UVM register model, C/C++ Headers, Python and documentation. All outputs are derived from the golden specification, a popular methodology employed by our customers to synchronise various SoC teams.
Startups in AI can easily implement SRAM-based register files. It does not completely solve the von Neumann bottleneck but it’s an inexpensive counter-measure. As the race for AI supremacy continues, new-generation chips will be deployed, new research will be conducted and new requirements will arise. As a result new bottlenecks will naturally show up so favouring the least expensive solution to a given problem is a practical choice. Time will tell who will dominate in this race, and I’m for sure excited to see!