Louie De Luna
AGNISYS Director of Sales and Marketing

Louie De Luna
AGNISYS Director of Sales and Marketing
Right after Google’s AlphaGo system defeated a human Go world champion in 2015, the hype of deep learning and machine learning (ML) was quickly assimilated into mainstream technology.
—
In EDA, the application of ML algorithms actually dates back to 2008 – when two Machine Learning-related topics were presented at DAC. The first topic, Efficient System Design Space Exploration Using Machine Learning Techniques targeted design challenges and the second, Experiences and Advances in Formal and Dynamic Verification, targeted verification challenges.
As a company focused on solving both design and verification challenges associated to Hardware/Software Interface (HSI), Agnisys has extensive experience in register code generation and verification, so applying Machine Learning to register automation is a natural next step for us. Agnisys register tool IDesignSpec is a fully-matured solution with a large user base, where it can generate register code directly from the specification in Word, Excel, IP-XACT or SystemRDL. But in an ideal world, our users would rather use plain and simple English text to describe the register behaviour rather than use special properties and syntax. Natural, plain English is still the hallmark of specifications in today’s system design and a lot of useful and actionable information is embedded in the natural language specification text.
Our R&D is always up to the challenge, so we looked at the problem and tried to figure out how to solve it by applying Machine Learning. The main problem statement is as follows:
Can we accurately predict the register description (architecture, data flow, register name, field size, default value, offset and access type) by identifying patterns in plain text written in simple English?
By applying ML to solve the given problem, our users would be able to simply use IDesignSpec and generate the corresponding register code appropriate to the identified register description. The register code includes RTL, UVM regmodel, C/C++ Headers, HTML/PDF documentation and the required UVM testbench with positive/negative sequences to test special registers such as Lock, Alias, Trigger-Buffer, Counter, Shadow and Paged registers.
Machine Learning Algorithm
The problem can be solved by applying a Supervised Classification Algorithm where the data is classified into multiple classes. In this case the data is classified into the following classes that are also used as labels:
Our R&D team used Python for coding the ML algorithm and Keras for the required Deep Learning Libraries running on top of Tensorflow. Keras and Tensorflow are both required as they already have a vast library of high-level neural network APIs, models and layers.
The classification was made by aggregating thousands of register specification and commonly used registers. The dataset is a collection of tens of thousands of register description in English text. A small sample of the dataset is shown in Figure 1. The Machine Learning algorithm was trained with different description for each type of registers.

Figure 1: Sample description Dataset for Lock/Key register fields
Results and Next Steps
The results of the prediction are quite promising and shown below. Figure 2 shows the training data for the Lock register. The description column contains the functionality of the register in simple English text. The Src Reg and Src Field columns contain the register and field name. In general, a Lock register depends upon a Key register for any action to take place (read, write, set or clear). They are represented in the columns Lock Reg, Lock Field, Key Reg and Key Field correspondingly. The output column represents the predicted IDS property. The accuracy of the predicted output from the ML model for the sampled data was about 75%.
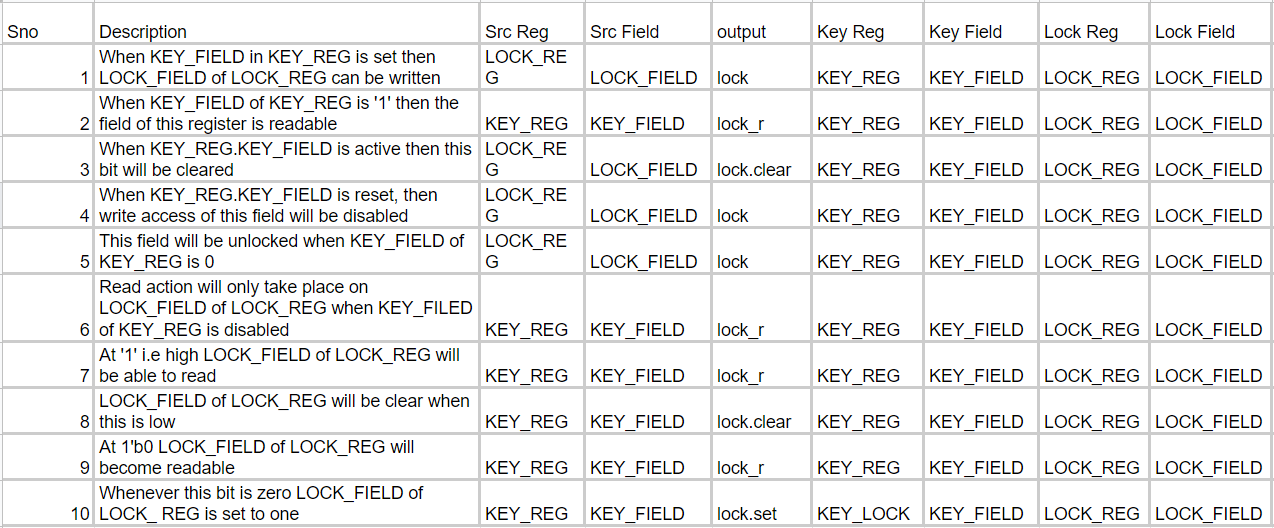
Figure 2: Sample training dataset for Lock/Key register
Similarly, other types of registers can be predicted just by the describing the registers functionality. All types of registers such as interrupt, shadow, alias, FIFO, counter can be predicted through the ML algorithm. Once the property is identified, IDesignSpec can take the input spec and create the necessary register files including RTL, UVM, SystemC and HTML/PDF.
This type of ML algorithm for register automation holds great value for the future. As next steps, we plan to extend the scope to capture various register functionalities and nature, including the number of times a register is repeated, the reset type of the register, and the clock domain crossing description. The basic features of registers such as name, width, offset, default value and access type can also be accommodated so that we can cover the entire register spec from basic to complex.
The time where we can generate the entire RTL code by simply specifying the functionality of registers in plain English language is not far away. We are in a very exciting time where technology is increasing exponentially. The benefits of ML are quite significant because it can be applied to many aspects of technology that can ultimately improve our lives, and both the Semiconductor and EDA industries are in pivotal roles to its success.
New generations of hardware accelerator chips that are flexible and re-programmable are needed because the algorithms are dynamically changing. New innovations within the EDA tools are happening now, and many tool vendors are looking to solve design and verification problems by applying ML algorithms.
At DVCon US 2019, you will find numerous Machine Learning-related presentations, tutorials and workshops, and one of them will be presented by one of my colleagues, Nikita Gulliya, Agnisys R&D Engineer.
For more, I invite you to download our paper presentations on Register Automation using Machine Learning that were presented at DVCon 2019.
White Paper: Using Machine Learning in Register Automation and Verification